― 外国税額控除の申告を楽にしたかっただけなのに ―
配当明細書のPDFは、投資をしているといつの間にか当たり前のように溜まっていきます。
証券会社のサイトからダウンロードして、金額を確認して、スプレッドシートに転記する。一回一回は大した作業ではありません。
慣れてしまえば数分で終わりますし、特別なスキルが必要なわけでもありません。
ただ、この作業には独特の疲れがあります。数字を扱う以上、ミスは許されない。
あとで見返す可能性もある。特に外国株の配当は、外国税、国内課税、為替レートなどが絡むため、国内配当よりも確認項目が多くなります。
毎回そこまで神経をすり減らしているつもりはなくても、終わった後にじわっと疲れが残る。そんな感覚でした。
しかも、これは一度きりの作業ではありません。配当は毎年、毎月、投資を続ける限り確実に発生します。
国内株だけならまだしも、外国株や海外ETFを保有していると、最終的には確定申告、しかも外国税額控除という避けて通れない作業が待っています。
「これ、ずっと手でやり続ける前提なのか?」
そんな違和感が、今回の話の出発点でした。
私は普段、SBI証券を中心に投資をしています。国内株、国内ETF、米国株、海外ETF。配当明細書のPDFも、気づけばかなりの数になっていました。
Google Driveは日常的に使っているし、GASもそれなりに触っています。
ここで一度補足しておくと、GAS(Google Apps Script)というのは、Googleが用意している自動化用の仕組みで、「GoogleスプレッドシートやDriveを自動で操作する道具」くらいの理解で十分です。プログラミング経験がなくても、考え方自体は「作業の自動化」に近いものです。
正直、この時点ではこう思っていました。
「外国税額控除用のデータ整理くらい、機械にやらせられるでしょ」
なぜ配当明細をOCRで自動化しようと思ったのか
今回の自動化の目的は、実はそれほど大げさなものではありませんでした。
私が楽にしたかったのは、外国税額控除の申告書類を作るための下準備です。
国内配当や国内ETFの分配金については、基本的に特定口座(源泉徴収あり)で完結します。
数字として管理はしたいので入力はしますが、確定申告書そのものには載せません。申告対象外です。
一方で、外国株や海外ETFの配当については話が変わります。外国で源泉徴収された税額を、日本の税額から控除するためには、次のような情報を年単位で正確に集計する必要があります。
- 銘柄ごとの配当額
- 外国で源泉徴収された税額
- 支払日
- 為替レート
ここがとにかく面倒です。
SBI証券の年間取引報告書を見れば、ある程度まとまった数字は載っています。ただ、外国税額控除の申告では「銘柄ごとの内訳」や「配当ごとの税額」が必要になる場面があり、結局は配当明細書PDFを一枚ずつ確認することになります。
つまり、
- 国内配当・国内ETF
→ 管理用として入力はするが、申告書からは除外 - 外国株・海外ETF
→ 外国税額控除のために、正確なデータが必要
という二重構造になっていました。
「外国税額控除に必要な情報だけでも、自動で整理できたら相当楽になるのでは?」
そう考えたのが、OCR自動化に手を出した直接の理由です。
OCRとは何をしているのか(プログラミング未経験向け)
ここで少しだけ、OCRについて説明しておきます。
OCRとは、「画像やPDFに書かれている文字を、テキストデータとして読み取る技術」です。人間がPDFを目で見て数字を確認する代わりに、コンピュータに読ませるイメージです。
今回やろうとしていたのは、単純に言えば、
- 配当明細書PDFを
- コンピュータに読ませて
- 数字を自動で抜き出す
ということでした。
人がやっている作業を、そのまま機械に置き換える。
だからこそ、「これはいけそうだ」と思えたのだと思います。
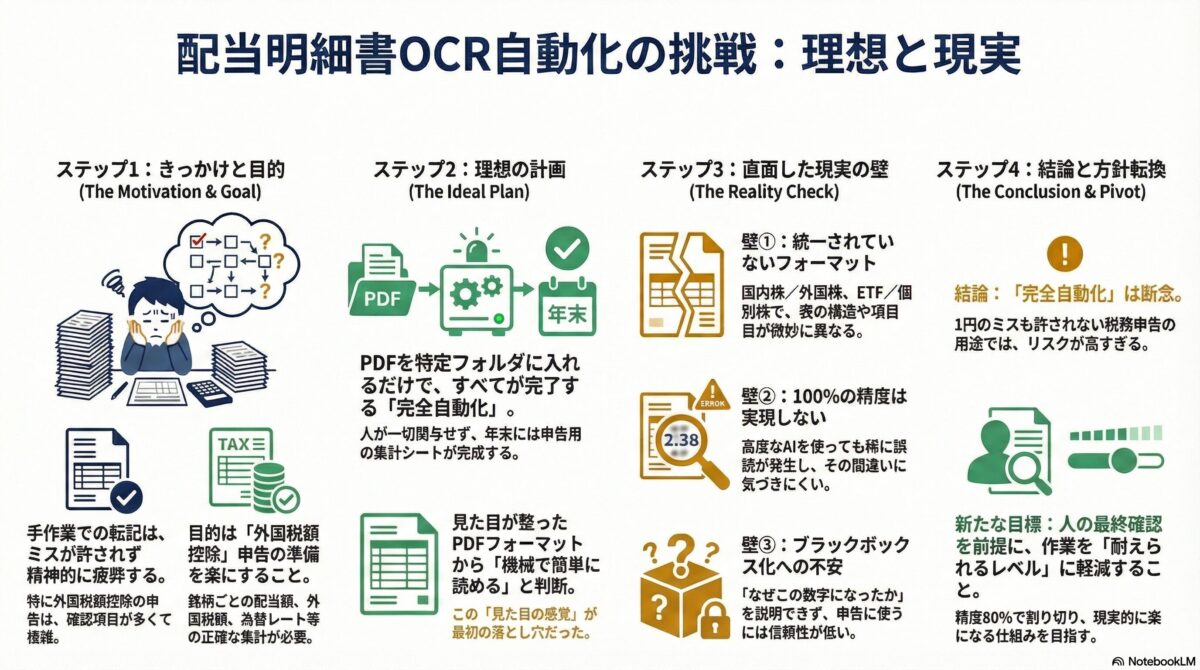
最初に思い描いていた「理想の完全自動化」
当時、頭の中にあった理想像はとてもシンプルでした。
SBI証券から配当明細書のPDFをダウンロードし、Google Driveの特定フォルダに入れる。
あとはOCRで必要な項目を読み取り、配当管理用のスプレッドシートに自動転記する。国内配当も外国配当も一旦はすべて入力するが、申告用の集計では外国配当だけを抽出する。人は一切関与しない。
PDFを放り込んだら、あとは何もしなくていい。
年末になったら、外国税額控除用の集計シートが完成している。
「これができたら、確定申告のストレスはほぼ消える」
そう本気で思っていました。
SBI証券の配当明細書は、フォーマットとしては比較的オーソドックスです。項目も整理されていて、「いかにも機械で読ませやすそう」に見えました。
今振り返ると、この「見た目で判断した感覚」が、最初の落とし穴だったのだと思います。
実際にやってみて見えてきた現実
実装そのものは、思ったほど難しくありませんでした。Google Drive上のPDFをテキストに変換し、行ごとに分解して、それっぽい数字を拾っていく。最初の数枚は確かにうまくいきました。
「お、これならいけるかも」
ただ、処理するPDFが増えるにつれて、少しずつ違和感が出てきます。
同じSBI証券の配当明細書なのに、完全に同じフォーマットではありません。国内株と外国株で表構造が違う。ETFと個別株で項目の並びが微妙に異なる。為替レートが記載されている明細と、されていない明細がある。
人間なら「まあそういうものか」で読み飛ばせる差異が、機械にとっては致命的になります。
「精度を上げれば解決する」と思った
そこで次に考えたのが、「もっと賢く読ませればいいのでは?」という発想でした。OCRの精度を上げれば、こうした差異も吸収できるはずだ、と。
ここで登場するのが、Vision API や Gemini といった技術です。ざっくり言えば、「普通のOCRより、もう少し頭のいい読み取り方法」だと思ってください。
実際、精度は目に見えて改善しました。数字の拾い漏れは減り、表構造の再現度も上がりました。「これは人間が読むより正確なのでは?」と感じる場面すらあります。
ただ同時に、別の不安も出てきました。
「この数字、なぜこうなったんだっけ?」
外国税額控除は、税務署に提出する申告書類です。理由を説明できない数字を、そのまま信じていいのか。
便利さと引き換えに、自分で把握できない部分が増えていく感覚がありました。
それでも、完全自動化にはならなかった
精度が上がるほど、別の問題がはっきりしてきます。100%にはならない。たまに致命的な誤読が混ざる。そして何より、その誤りに気づきにくい。
外国税額控除は、1円単位で積み上げた結果を申告します。どこかで数字がズレると、控除額全体が変わってしまう。「どこかで間違っているかもしれない」という前提で数字を見るのは、想像以上にストレスがかかります。
ここで、ようやく立ち止まりました。
「これ、人が最後に確認しない前提で使える?」
答えは、正直なところ NO でした。
いったん結論:完全OCR自動化は諦めた
この時点で、配当明細書の完全OCR自動化は諦めました。技術的に不可能、という話ではありません。ただ、
- 外国税額控除という申告用途で使うこと
- 国内配当と外国配当が混在していること
- ミスが後から発覚するリスク
を考えると、完全自動化は現実的ではありませんでした。
欲しかったのは、人を完全に排除する仕組みではなく、申告作業を「耐えられるレベル」にすることだったのだと思います。
この先で書くこと
このあと、考え方を大きく変えました。精度80%で割り切る運用。外国税額控除に必要な部分だけを重点的に扱う設計。国内配当や国内ETFは管理用として入力するが、申告集計からは除外するという割り切り。
次回以降の記事では、
- なぜ80%で止めたのか
- プログラミングを知らなくても理解できる設計の考え方
- 外国税額控除前提で「現実的に楽になる」ライン
を、体験ベースで書いていきます。
外国税額控除を毎年やっている人ほど、
「これ、分かる」と思ってもらえる話になるはずです。
コメント